GPT-2で作ったConoHa上のこのはちゃんbotとSlackで会話する
はじめに
この記事はConoHa Advent Calendar 2022の11日目の記事です。
ConoHa Advent Calendarは初めての投稿です。どうぞよろしくお願いいたします。
ConoHa、いいですよね。課金が時間単位、転送量課金がない、スケールアップ・スケールダウンが可能、と使い勝手がいいですが、何より美雲このはちゃんが清楚かわいいのでモチベーションが上がります。
Advent Calendarの記事のテーマを考えながらConoHa上で作業をしていたときにふと思いました。ConoHaでの作業の合間にこのはちゃんとおしゃべりできたら楽しそうだなと。個人的にちょうどGPT-2にも興味を持っていたのです。技術の力で何とかなるかもしれませんね?
というわけで、自然言語処理における深層学習モデルの一種であるGPT-2を利用して、文章を入力すると「このはちゃんっぽい」返事を出力するモデル(このはちゃんモデル)を作成しました。このモデルを組み込んだSlackのチャットボットのAPIをConoHa VPS上に立て、Slackでこのはちゃんbotとおしゃべりしてみました。なお、このはちゃんモデルを作成する際には、Twitterのこのはちゃん(@MikumoConoHa)へのメンションのツイートとそれに対するこのはちゃんのリプライのテキストデータを用いています。
技術的には、GPT-2の推論モデルを組み込んだSlack botのAPIをConoHa上にFastAPI + Boltで立てました。FastAPIはPythonのAPIフレームワーク、BoltはSlack botを作れるSlack公式のライブラリです。モデルはrinna社の日本語の事前学習済みGPT-2モデルであるjapanese-gpt2-smallをツイートデータでファインチューニングすることで作成しています。

記事の流れは以下の通りです。
- 学習データの入手(ローカルPC)
- ツイートを収集する
- 1のテキストを前処理する
- このはちゃんモデルの作成(ローカルPC)
- ローカルPCに環境を構築する
- ファインチューニングする
- このはちゃんモデルを組み込んだSlack botのAPIをデプロイ(ConoHa VPS)
- Slack APIのWebサイトよりEvent Subscription型のSlackアプリを作成する
- 2-2で作成したこのはちゃんモデルを組み込んだSlack botのAPIをVPSにデプロイする
環境
ローカルPC
- OS、ハード
- Windows 10
- NVIDIA GeForce RTX 2060 Super
- CUDA 11.6
- CuDNN 8.5.0
- Python
- python 3.10.4 (miniconda 4.10.3)
- torch 1.12.1+cu116
- transformers 4.22.0.dev0
- sentencepiece 0.1.97
- R
- R 4.2.1 (RStudio 2022.07.1+554 Spotted Wakerobin (desktop))
- rtweet 1.0.2
- rvest 1.0.3
ConoHa VPS(メモリ2GB)
- OS
- Ubuntu 22.04.1 LTS
- Python
- python 3.10.4 (miniconda 4.12.0)
- fastapi 0.79.0
- slack-bolt 1.14.3
- gunicorn 20.1.0
- torch, transformers, sentencepieceはローカルPCと同じ
学習データの入手
(この章はConoHa VPSを使っていないので読み飛ばしていただいても構いません)
ツイートの収集
まずは後のファインチューニングの学習データとして使用するツイートを集めます。
いま作りたいチャットボットは、何かしらの問いかけをするとそれに対してこのはちゃんbotが返事をしてくれるというものです。ですから、学習データとして、@MikumoConoHaに対するリプライツイートと、それに対する@MikumoConoHaによるリプライのペアを集めればよいことになります。このようなツイートのペアを取得するには、まず@MikumoConoHaのツイートを取得し、次にツイートごとにツイートがリプライの場合はリプライ元のツイートを取得することになります。
ロジックは以下の通りです。
- @MikumoConoHaのツイートの取得
- 過去のツイートを保存しているtwilogというWebサイトの@MikumoConoHaのページより@MikumoConoHaのツイートをスクレイピングします。
- Twitter APIを用いれば指定したユーザのツイートを取得することができます。
- rtweet(RのTwitter APIクライアント)では
rtweet::get_timeline、tweepy(PythonのTwitter APIクライアント)ではtweepy.API.user_timeline
- rtweet(RのTwitter APIクライアント)では
- しかし、無料版では最新3200件しか取得できません。
- twilogには3200件の制約なく過去のツイートが掲載されているため、この方法をとりました。
- Twitter APIを用いれば指定したユーザのツイートを取得することができます。
- 過去のツイートを保存しているtwilogというWebサイトの@MikumoConoHaのページより@MikumoConoHaのツイートをスクレイピングします。
- @MikumoConoHaのツイートが他のツイートへのリプライである場合、そのリプライ元のツイートのIDの取得
- 上のスクレイピングで取得した@MikumoConoHaの各ツイートのID(
https://twitter.com/<user_name>/status/[0-9]+の[0-9]+)を用いてTwitter APIを叩くことで、各ツイートのテキストやメタ情報を取得します。メタ情報の中にはリプライ元のツイートのIDがin_reply_to_status_idとして含まれていますので、これを取り出します(ツイートが他のツイートに対するリプライでない場合はNULL)。- rtweetでは
rtweet::lookup_tweet、tweepyではtweepy.API.get_status - 細かい話ですが、非公式RTなどでは
in_reply_to_status_idがNULLになることがあるようです。
- rtweetでは
- 上のスクレイピングで取得した@MikumoConoHaの各ツイートのID(
- リプライ元のツイートのテキストの取得
- 上で入手したリプライ元のツイートのIDを用いて同じAPIをもう一度叩くことでリプライ元のツイートのテキストを得ます。
- なお、非公開アカウントからのツイートである場合は得られません。
- 上で入手したリプライ元のツイートのIDを用いて同じAPIをもう一度叩くことでリプライ元のツイートのテキストを得ます。
ローカルPC上で、R(rtweet + rvest)で取得しました。記事の他の部分はPythonを用いているのでこの節もPython(tweepy + requests + beautifulsoup)で書いて言語を統一してもいいのですが、以前Rで似たようなコードを書いていたのでそれを流用しています。スクレイピングやクローリングの定期実行はVPSの得意とする所ですが、今回は数時間、1回のクローリングでデータが得られるためローカルPC上で実行しています。
テキストの前処理
ここまでで入手したツイートのペアのテキストを前処理します。前処理あるあるだと思いますが、今回の記事で一番大変な工程でした。
まずはツイートからメンション記号(@)やリツイート記号(RT)などを取り除き、純粋なテキスト部分を取り出します。リツイートは複数連鎖していたり、メンション記号が複数付いていたりするので、正規表現で頑張って取り除きます。
そのうえで、通常のテキストの前処理を行います。全角チルダを波ダッシュに置換(いわゆる全角チルダ・波ダッシュ問題)、絵文字や顔文字、ハッシュタグの削除、NFKC正規化、記号の表記ゆれの統一(「、、」を「…」に置換するなど)を行っています。
ここまでできたら、後述のモデルに投入するために、リプライ元とリプライのツイートの各ペアを
<s>(リプライ元のツイートのテキスト)[SEP](それに対する@MikumoConoHaのリプライのテキスト)</s>
という形式で1行ずつ書き出したUTF-8のテキストファイルで出力します。ちなみに、リプライが複数往復している場合は複数行に切り分けられます。
例えば、こちらのこのはちゃんとあんずちゃんの微笑ましい(?)やりとりから、
やだねっ!
— 美雲このは☁️💙 (@MikumoConoHa) May 27, 2021
以下の学習データが作成されます。
<s>疲れちゃったこのはちゃんも手伝って〜![SEP]やだねっ!</s>
(絵文字を単純に削除したせいで「疲れちゃった」と「このはちゃん」がくっついてしまい、「このはちゃんが疲れた」ようにも読めますね。前処理の難しい所です。)
このテキストがペアの数だけ行として存在します。以上により、リプライ元のツイートと@MikumoConoHaのリプライのペアを約23000件(約2.5MB)集めることができました。
このはちゃんモデルの作成
(この章もConoHa VPSを使っていないので読み飛ばしていただいても構いません)
今回用いた手法であるGPT-2では、巨大な言語コーパスを学習データとした汎用的なモデル(事前学習モデル)をそのまま解きたいタスクに適用することもできますし、解きたいタスクのドメインに関する比較的少量のテキストを用いて事前学習モデルをファインチューニングすることでタスクに特化したモデルを作成することもできます。
一般に、「汎用的なモデル」を一から作るには膨大な計算資源が必要ですので、既に公開されているモデルを利用するのが定番です。事前学習モデルはりんなちゃんのrinna社が公開している日本語のGPT-2モデルであるrinnakk/japanese-pretrained-modelsのjapanese-gpt2-smallというモデルを用いました。よりサイズが大きいモデルも公開されていますが、私のローカルPCのGPUではメモリに載らなかったため、japanese-gpt2-smallを用いました。
このjapanese-gpt2-smallを先程作成したツイートデータでファインチューニングすることで、文章を入力するとそれに対するこのはちゃんっぽい文章を出力する(これが入力した文章に対する返信ということです)という今回解きたいタスクに特化したモデルを作るという流れです。
ConoHa VPSにはGPUインスタンスがないため、ファインチューニングはローカルPCで行い、できたモデルをConoHaに持っていくことにします。深層学習は素人なため、誤りがあったらすみません。
環境構築
まずローカルPCにPyTorchとCUDA, CuDNNの環境を作ります。CUDAとCuDNNはtorchでGPUを使うのに必要なものです。
環境構築はこちらの記事を参考にさせていただきました(ただし、この参考記事と違いPyTorch1.12 + CUDA 11.6 + CuDNN 8.5を入れました)。
Windows10にPyTorch1.10とCUDA11.3の環境を作る
CUDAとCuDNNを入れたら、以下を実行します。私はMinicondaの仮想環境の中でpipを用いています。
$ conda create -n conoha-chatbot python=3.10
$ conda activate conoha-chatbot
$ conda install pip
# 参照: [Start Locally | PyTorch](https://pytorch.org/get-started/locally/)
$ pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
# protobufのバージョンを3.20以下にするようにエラーが出るのでprotobufは3.20のバージョンを指定
$ pip install pip install sentencepiece datasets evaluate protobuf==3.20
$ pip install git+https://github.com/huggingface/transformers
$ cd <適当な作業ディレクトリ>
# あとでファインチューニングでスクリプトを使うため
$ git clone https://github.com/huggingface/transformers
ファインチューニング
こちらの記事を参考にさせていただきました。
GPT-2をファインチューニングしてニュース記事のタイトルを条件付きで生成してみた。 - Qiita
ファインチューニング用のファイルであるtransformersのrun_clm.pyの引数に先程作成した学習データとパラメータを渡せばOKです。
$ cd <作業ディレクトリ>
$ python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-small \
# 先程出力したデータのテキストファイルのファイル名
--train_file=conoha_training_data.txt \
--validation_file=conoha_training_data.txt \
--do_train \
--do_eval \
--num_train_epochs=100 \
--save_steps=10000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=model_output \
--use_fast_tokenizer=False
以上を実行して学習が終わるまで待つと、作業ディレクトリ内のmodel_outputというディレクトリにモデルが出力されます。学習データは約23000件(約2.5MB)、エポック数100、バッチサイズ1で学習に約4時間かかりました。
Slack botのデプロイ
ここからいよいよConoHa VPSを使います。
Slackアプリの作成
https://api.slack.com/ よりSlackアプリを作成します。
今回作りたいSlack botはEvent Subscriptionのbotです。これは、Slack上でメッセージを投稿するなど何かしらの動作をすると、指定したエンドポイントにSlackがリクエストを投げ、そのリクエストに対して何かしらのレスポンスを返すとSlackに反映されるというものです。
まずはSlack Appを作り、アプリにSlack上の権限を付与します。作り方はこちらの記事を参考にさせていただきました。
- Slack Appの作り方を丁寧に残す【BotとEvent APIの設定編】
- 【30分で完成】オウム返しBotから始めるSlackアプリの作り方 | PCIソリューションズ - プロダクト・サービスサイト
できたら、適当にSlackのチャンネルを作り、そのチャンネルにAppをインストールします。
また、このはちゃんとチャットしている雰囲気を出すために、Slack APIのWebサイト上からアイコンを設定しました。アイコンは美雲このはオフィシャルサイトの二次創作用イラストよりいただきました。
このはちゃんモデルを組み込んだSlack botのAPIのデプロイ
ようやくこのはちゃんbotのデプロイまでたどり着きました。FastAPI (Bolt) + Gunicornを用いて、Slack botのAPIを<VPSのIPアドレス>:8000に立てることにします。
実際は、独自ドメインを取ってSSL化した上でSlack APIのURLを
https://mydomain.example.com/slack/eventsに設定し、NginxでそのURL宛のリクエストを127.0.0.1:8000にリバースプロキシし、APIを127.0.0.1:8000に立てました。ここでは簡単のため独自ドメイン、SSL化、Nginxによるリバースプロキシを使わない前提で説明します。
まずはConoHa VPS上に使用するcondaの仮想環境を作り、次にFastAPI関連のライブラリと、SlackのEvent Subscription型のアプリを作れるSlack公式のSDKであるBoltというライブラリを入れます。
$ conda create -n conoha-chatbot python=3.10
$ conda activate conoha-chatbot
$ conda install pip
$ pip install fastapi pydantic uvicorn[standard] gunicorn
$ pip install slack_bolt
次にPyTorchの環境設定を行います。推論はCPUで行うので、CUDAやCuDNNのインストールは不要です。
$ conda activate conoha-chatbot
# 前処理で絵文字を削除するのに使う
$ pip install demoji
$ pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
$ pip install pip install sentencepiece datasets evaluate protobuf==3.20
$ pip install git+https://github.com/huggingface/transformers
次に、先程訓練したモデルが入ったローカルPCの"model_output"ディレクトリ以下を、VPSの作業ディレクトリ直下に移します。
そして、以下のmain.pyとgenerate.pyをそれぞれ作業ディレクトリ直下に作成します。
ディレクトリ構成はこのようになっています。
$ tree -L 1 <作業ディレクトリ>
<作業ディレクトリ>
├── generate.py
├── main.py
└── model_output
main.py
コード内の二つのcredentialはSlack APIのポータルサイトより得られる値を記入します。
- SLACK_BOT_TOKEN
- 左サイドバーの「OAuth & Permissions」ページ内の「Bot User OAuth Token」(xoxb-で始まる文字列)
- SLACK_SIGNING_SECRET
- 左サイドバーの「Basic Information」ページ内の「Signing Secret」
from slack_bolt import App
from slack_bolt.adapter.fastapi import SlackRequestHandler
from fastapi import FastAPI, Request
from generate import preprocess, generate
# 自分のcredentialを入れる(コード内に書かず、環境変数として切り出す方が望ましい)
SLACK_BOT_TOKEN = "xoxb-xxxxxx"
SLACK_SIGNING_SECRET = "xxxxxx"
app = App(token=SLACK_BOT_TOKEN, signing_secret=SLACK_SIGNING_SECRET)
app_handler = SlackRequestHandler(app)
# 引数のroot_pathはNginxなどでリバースプロキシするときに変える(今回はルートのまま)
api = FastAPI(root_path="/")
@api.post("/")
async def endpoint(req: Request):
return await app_handler.handle(req)
# 「Slackにメッセージが投稿されたらこの関数を実行する」という意味のデコレータ
@app.event("message")
def handle_app_mentions(body, say, logger):
text = body["event"]["text"]
res: list[str] = generate(preprocess(text), 1)
res: str = res[0]
print(f"input: {text} - output: {res}")
say(res)
generate.py
import re
import unicodedata
import demoji
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = torch.device("cpu")
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-small")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("<作業ディレクトリ>/model_output/")
model.to(device)
def preprocess(text: str) -> str:
"""
テキストを前処理する
"""
# windowsの全角チルダを波ダッシュに変換する(いわゆる全角チルダ・波ダッシュ問題)
text = re.sub("\uff5e", "\u301c", text)
# 絵文字を削除
text = demoji.replace(text, "")
text = unicodedata.normalize("NFKC", text)
# 顔文字を雑に削除
text = re.sub(r"[\((].*[\))]", "", text)
# URLを削除
text = re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-]+", "", text)
# ハッシュタグを削除
text = re.sub(r"#.+ ?", "", text)
# 表記ゆれ系を統一
text = re.sub(r"[・、。]{2,3}", "…", text)
text = re.sub(r"\.\.\.", "…", text)
text = re.sub("ー{2,}", "ー", text)
text = re.sub(r"!{2,}", "!", text)
text = re.sub(r"\?{2,}", "?", text)
text = re.sub(r"…{2,}", "…", text)
text = text.strip()
return text
def generate(input: str, num: int = 1) -> list[str]:
"""
推論する
引数inputのテキストからnum個のテキストを作る
"""
input_text = "<s>" + input + "[SEP]"
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
# ここのパラメータを変えると出力される文章が変わる
out = model.generate(
input_ids, do_sample=True, top_p=0.95, top_k=500, repetition_penalty=1.2,
num_return_sequences=num, max_length=30, bad_words_ids=[[1], [5]]
)
res = []
for output_text in tokenizer.batch_decode(out):
output_text = output_text.split("[SEP]</s>")[1]
output_text = output_text.replace("</s>", "")
res.append(output_text)
return res
技術的な説明
- APIの起動時にこのはちゃんモデルがロードされます。
- Slack Appをインストールしたチャンネルで何らかのメッセージを入力すると、そのメッセージを含むJSONがこのAPIにPOSTされます。
- API側では以下の処理が行われます。
- 実際にSlackに入力されたテキストをJSONから取り出します。
- それをテキストの前処理関数である
preprocessで前処理します。- ローカルPCでの前処理の際に使用した関数と同じものです。
- モデルに通すために、前処理した入力するテキストを
<s>(入力するテキスト)[SEP]の形の文字列にします。 - これをこのはちゃんモデルに通し、出力の文字列を得ます。
- Slack側にレスポンスを返します。
Slackにメッセージが投稿されたらそれを受け取って何かしらのレスポンスを返すという処理は、Boltを使わずrequestsなどを使って自分で一から作ることもできますが、結構骨が折れます。Boltはデコレータによってこの処理を簡単に記述できるライブラリです。BoltにはHTTPServerアダプタが組み込まれているためBolt単体でもAPIを立ち上げられますが、FastAPIやFlaskのようなAPIのライブラリにBoltを組み込むことができます(公式のドキュメントでは、本番環境ではそうすることが推奨されています)。BoltのFastAPIへの組み込み方については、BoltのGitHubライブラリ内のサンプルコードを参考にしました。
テキストを与えると返事を出力するGPT-2の推論部分を別のAPIとして作成し、Slack botのAPIではそのAPIを叩きに行くのがよくある構成だと思いますが、簡単のためbotのAPI内で直接モデルをロードすることにしました。
APIのデプロイ
アプリケーションサーバにGunicornを用いて、このAPIを8000番ポートで公開します。事前にファイアウォールで8000番ポートを開けておきます。
$ cd <作業ディレクトリ>
$ python -m gunicorn main:app --bind 0:0:0:0:8000 -w 1 -k uvicorn.workers.UvicornWorker
Gunicornのワーカー数(-w 1の部分)は1にしています。各ワーカーでこのはちゃんモデルがロードされるため、メモリ2GBのプランではメモリ使用量的にワーカー数は1がギリギリでした。なお、VPS(CPU3コア、メモリ2GB)にssh接続した状態でメモリ使用量(sar -rコマンドの%memused)を確認してみると、APIの起動前は10%、起動直後(モデルをロードしているとき)は50%、メッセージ待機時と推論時は40%程度を推移していました。
APIエンドポイントをSlackに登録する
先程Slack Appを作成したSlack APIのWebサイトより、左サイドバーの"Event Subscriptions"を開きます。画像の"Enable Events"の横のトグルをOnにした後、今立ち上げたAPIエンドポイントのURLをRequest URLの欄に入力します。
画像内の"Request URL"にhttp://<VPSのIPアドレス>:8000を入力します。
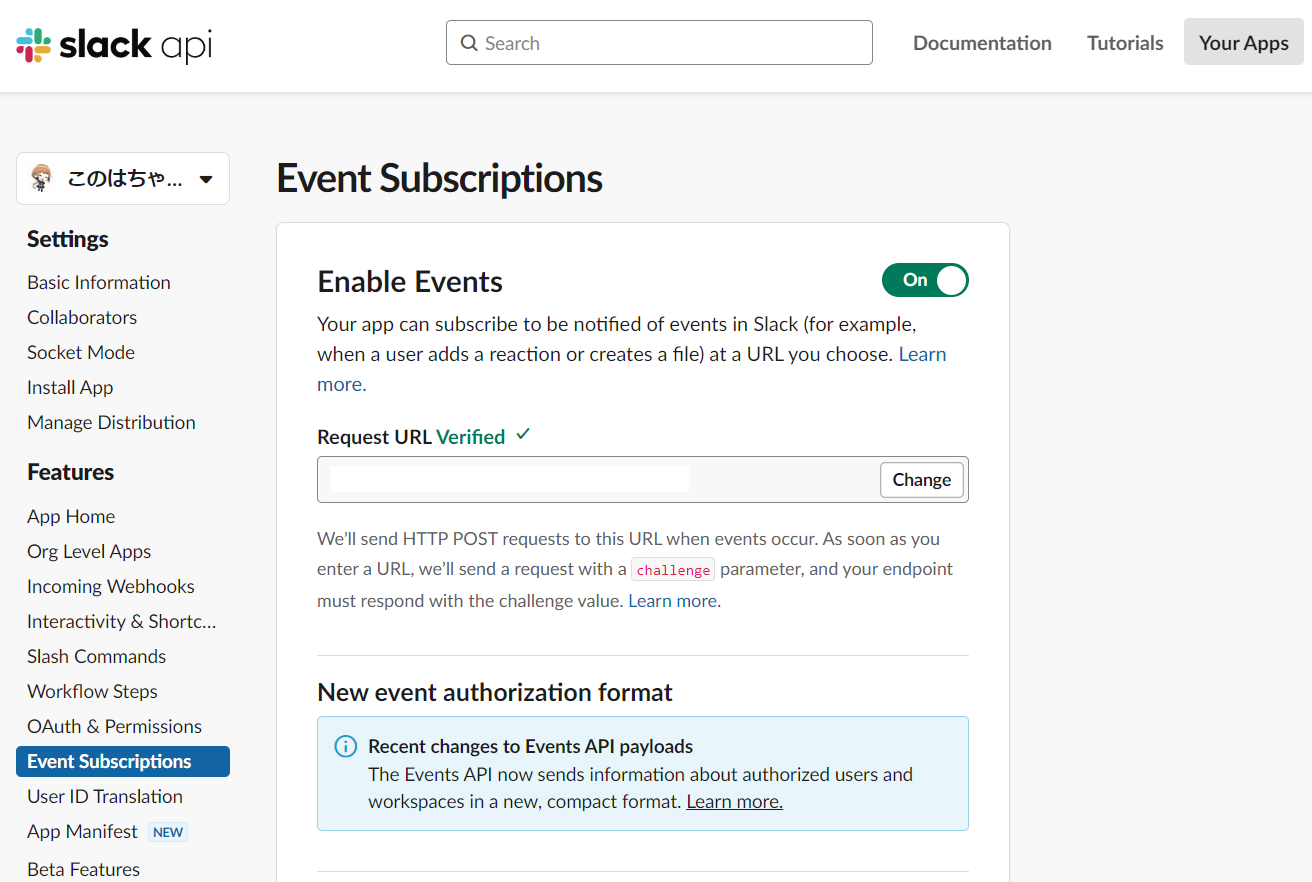
入力するとSlack側から立ち上げたAPIにドメインの所有権を確かめるためのPOSTが行われます。上手くAPIが立ち上げられていれば、bolt側でこれを打ち返してくれるので、“Verified"と表示されるはずです。
最後にSlack Appをインストールしたチャンネルに適当にメッセージを入力してみて、数秒経ってからこのはちゃんbotから返事が来れば成功です。
APIのURLの初回登録時は、ドメインの所有権を確認するために、SlackからPOSTされるjsonの"challenge"というキーの値を送り返す必要があります(画像の"We’ll send HTTP POST requests to this URL when events occur.(以下省略)“に書いてある通り)。上記で利用したBoltでAPIを立てるとこの対応を内部で行ってくれますので、この処理に関するコードを書く必要はありません。 Boltを用いない場合はFastAPIなどのAPIフレームワークを使って自分でAPIを立てて対応する必要があります。詳細はSlackの公式ドキュメントをご参照ください。
会話してみた
会話してみます。
おはようと挨拶するとちゃんとおはようと返してくれます。ちなみに、このはちゃんモデルは文脈は考慮しません。(前のやり取りを踏まえて次の出力の文章が変わるということはありません)

こんばんはと挨拶してもおはようとしか返してくれません。謎の冬季限定チョコレート推し…。

清楚かわいいとほめると喜んでくれます。

あんずちゃんにはたまに厳しくなるみたいです。


おわりに
雰囲気は何となくこのはちゃんっぽい感じがしますね。個人的には満足しましたが、意味が通っていない返事をすることも結構ありました。前処理の改善やよりパラメータ数の大きい事前学習モデルの使用、パラメータチューニングなどが今後の課題でしょうか。
以上、ConoHa VPSでAPIを立てて深層学習チャットボットを作ることができました。今後もConoHaで物を作っていきたいです。
参考
- 公式ドキュメントなど
- Twitter: @MikumoConoHa
- 美雲このはオフィシャルサイト
- 本記事の中で使用したこのはちゃんのイラストはこちらからいただきました。
- ©GMO Internet Group, Inc., 再利用禁止です。
- りんなオフィシャルサイト
- rinnakk/japanese-pretrained-models
- rinna社による日本語GPT-2の事前学習モデル
- Slack | Bolt for Python
- BoltのGitHubライブラリ内のサンプルコード
- Using the Slack Events API | Slack
- 参考にさせていただいたサイト
- WindowsにおけるPyTorchのGPU環境の作り方
- rinnakk/japanese-pretrained-modelsの使い方
- Slack Appの作り方