ニコニコ動画の再生数の推移を見られるWebアプリを作った
概要
ニコニコ動画の動画について、再生数、マイリスト数、コメント数、いいね数の日次の推移を表示するWebアプリを作りました。
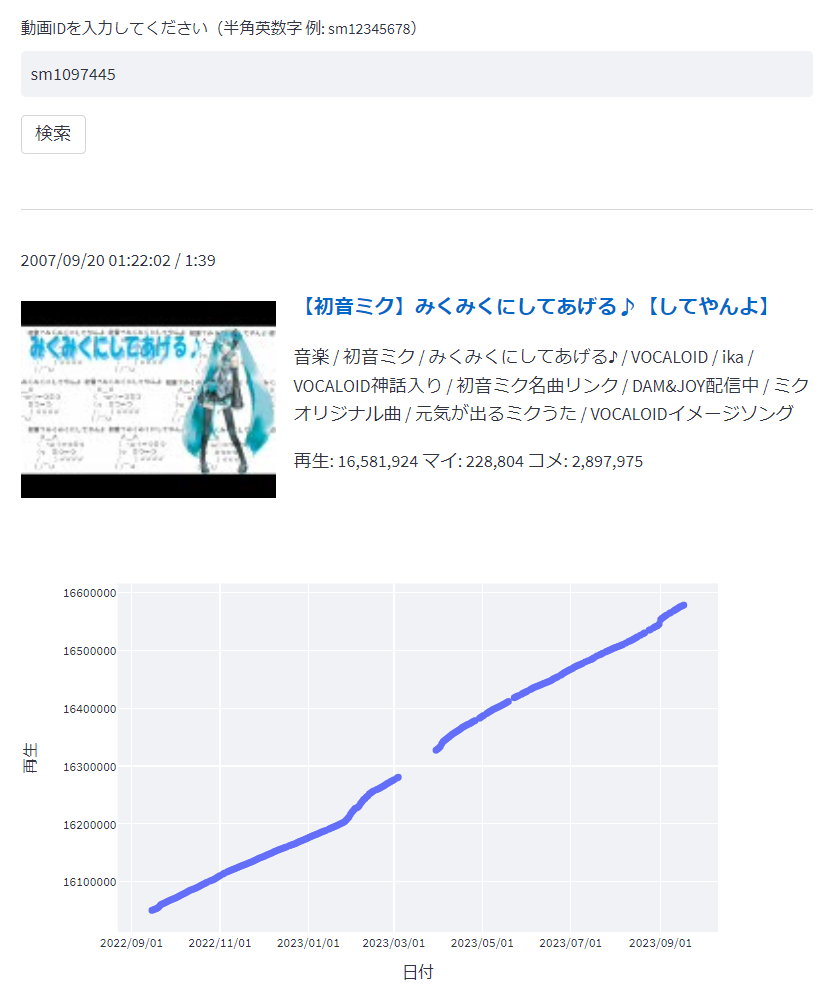
こんな感じで、動画のIDを入力すると過去の値を表示します。対象は再生数が3000以上の動画(2023/9/19時点で410万件程度)です。
技術構成
当日の断面における個々の動画の再生数などのメタデータを返すスナップショット検索API v2というAPIをニコニコ動画が公開しています。このAPIは当日分のデータしか返さないため、毎日リクエストしてデータを蓄積しています。
面白そうなデータなので毎日貯めているのですが、このような過去の再生数を表示するWebサイトはほとんどない1こともあり、勉強も兼ねてデータ基盤とWebアプリを作りました。
構成図はこちらです。
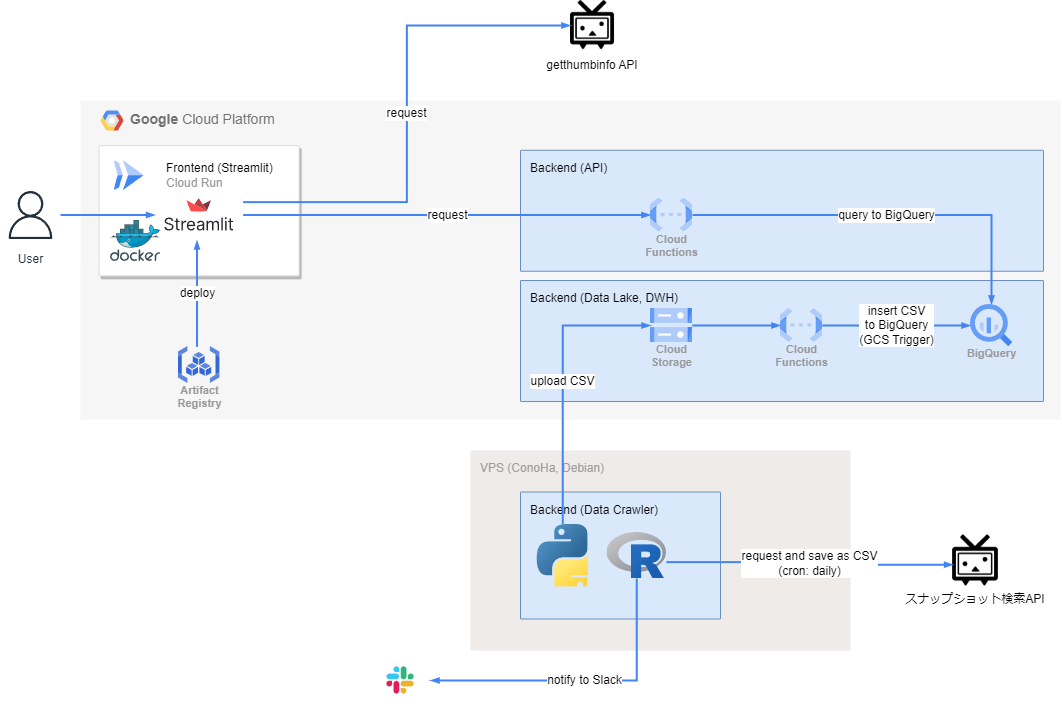
- バックエンド
- クローリング部分 (VPS, Debian)
- cronで1日1回スナップショットAPIをリクエストして結果のCSVを保存する (R)
- ここだけRなのは、過去にRで書いたコードを流用したから
- CSVファイルをCloud Storageにアップロードする (Python)
- cronで1日1回スナップショットAPIをリクエストして結果のCSVを保存する (R)
- データ基盤部分 (Google Cloud)
- CSVファイルがCloud StorageにアップロードされたらBigQueryに書き込むCloud Functions (Python)
- 過去の再生数などを保持するBigQuery
- 動画IDをクエリストリングに与えるとBigQueryをクエリして過去の再生数などを返すCloud Functions (Python)
- SQLインジェクション対策のため、フロントエンドだけでなくバックエンドでも入力値をバリデーション
- クローリング部分 (VPS, Debian)
- フロントエンド (Google Cloud)
- Cloud Run (Streamlit)
- Artifact RegistryにpushしたDocker imageでdeploy
- 以前はHerokuにdeployしていたが、Heroku代が高いのでCloud Runに引っ越した
- バックエンドとフロントエンドをGoogle Cloudに揃えたことにより、バックエンドのCloud Functionsをリクエストする認証周りがすっきりするメリットもあった
- Cloud Run (Streamlit)
VPS部分のコードは、GitHub Actionsを使って、mainブランチにpushするとVPSにデプロイ(git pull)しています。Google Cloud部分のコードはTerraformで定義しています。
クローリング・スクレイピングはVPS (cron)、データ基盤はBigQuery + Terraformというのは気に入っている構成でよく採用しています。
前者にVPSを利用するのは、長時間のクローリングでも気にせずコードを動かせることと、アウトバウンドの通信量に課金がされないことからです。Cloud FunctionsやCloud Runは実行時間に上限があるので、引っかかる場合は処理をうまく分割してあげる必要がありますが、VPSならcronで雑にスクリプトを動かせます。
なお、VPSのディスク容量などの監視ツールとして、はてな製のサービスであるMackerelを使っています。無料プランでは過去のメトリクスが1日分しか見られませんが、トリガーに引っかかったときはメールやSlackで通知でき、個人開発の心強い味方です。
技術的なTips
BigQueryのテーブル設計: パーティショニング
BigQueryのテーブルを一部抜粋します。カラムは順に日時、動画ID、再生数を表します。
| lastModified | contentId | viewCounter |
|---|---|---|
| 2023-09-15T08:59:37+09:00 | sm1097445 | 16575782 |
| 2023-09-16T08:53:20+09:00 | sm1097445 | 16576909 |
| 2023-09-17T08:52:41+09:00 | sm1097445 | 16578086 |
フロント側でデータを取得する際、例えば取得したい動画IDをsm1097445とすると、以下のクエリを書くことになります。
SELECT lastModified, contentId, viewCounter
FROM TABLE_NAME
WHERE contentId = "sm1097445"
ORDER BY lastModified;
クエリ量を削減するためにこのテーブルにパーティショニングを設定します。where句で絞るcontentIdでパーティショニングしたいところですが、パーティショニング可能なのは整数範囲、時間単位、取り込み時間のいずれかです。
contentIdはアルファベットの小文字2文字+数字1文字以上で表されることを利用し、contentIdの数字部分を4000で割った余りであるidModという列をテーブルにwrite_appendする際に付け加え、この列でパーティショニングすることにしました。4000というのは、当時BigQueryの整数範囲パーティショニングの上限は4000個までだったからです。
| lastModified | contentId | viewCounter | idMod |
|---|---|---|---|
| 2023-09-15T08:59:37+09:00 | sm1097445 | 16575782 | 1445 |
| 2023-09-16T08:53:20+09:00 | sm1097445 | 16576909 | 1445 |
| 2023-09-17T08:52:41+09:00 | sm1097445 | 16578086 | 1445 |
SQLでパーティショニングのidMod列をwhere句に含めることで、理想的にはクエリサイズが1/4000に抑えられます。
SELECT lastModified, contentId, viewCounter
FROM TABLE_NAME
WHERE contentId = "sm1097445" and idMod = 1445
ORDER BY lastModified;
今回はcontentIdでフィルタするクエリを書くためにこのようなパーティショニングを設定しましたが、例えば同一のlastModifiedにおけるレコードを全件取得するような使い方をするならlastModified列で時間単位パーティショニングすることになります。
Terraformの環境分け(本番環境と開発環境)
Google Cloud部分は、本番環境(prod)と開発環境(dev)を分けられるように定義しています。
Terraformで異なる環境を作成する方法としては以下の三つがメジャーなところかと思いますが、三番目の方法を取っています。
- Terraform Workspacesを使う
- moduleを使う
.tfbackendファイルと.tfvarsファイルを用いて変数で環境を分ける
具体的にはこちらです。
- リソース名の先頭に環境名を付ける(例:
prod-hoge-bucket) - 環境名を
prod.tfvars,dev.tfvarsに記載する - Terraformのstatusを管理するCloud Storageの情報を
prod.tfbackend,dev.tfbackendに記載する
小規模のバックエンド基盤では楽な方法ですね。
詳細には、こちらの記事(Terraformでmoduleを使わずに複数環境を構築する)が丁寧に解説されています。
もう少し説明
ディレクトリ構成はこのような感じです。
.
└── terraform
├── envs
│ ├── dev
│ │ ├── dev.tfbackend
│ │ └── dev.tfvars
│ └── prod
│ ├── prod.tfbackend
│ └── prod.tfvars
├── main.tf
└── variables.tf
main.tfは以下の通り
provider "google" {
project = var.project_id
region = var.project_region
}
terraform {
# バージョンは任意
required_version = "~> 1.5.5"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 4.80.0"
}
archive = {
source = "hashicorp/archive"
version = "~> 2.4.0"
}
}
backend "gcs" {
# envs/(env_name)/(env_name).tfbackendに定義
}
}
# 例えばCloud Storageのバケットを作成してみる
resource "google_storage_bucket" "tmp_bucket" {
name = "${var.env}-tmp-bucket"
location = var.project_region
force_destroy = var.env == "prod" ? true : false
}
envs/dev/dev.tfvarsは以下の通り
env = "dev"
project_region = "<PROJECT_REGION>"
project_id = "<PROJECT_ID>"
envs/dev/dev.tfbackend(stateを置くバックエンドのCloud Storageの情報)は以下の通り
bucket = "<BUCKET_NAME>"
prefix = "<PREFIX>"
variables.tfは以下の通り
variable "env" {
type = string
description = "environment name"
}
variable "project_region" {
type = string
description = "Google Cloud Region"
}
variable "project_id" {
type = string
description = "Project ID"
}
以上のように用意して、terraform initするときにtfbackendファイルを、terraform planとterraform applyするときにtfvarsファイルをオプションで渡すことで、環境ごとに異なるバックエンドを参照して異なるリソースを作成することができます。
# dev環境にdeployする
$ cd terraform
$ terraform init -backend-config=envs/dev/dev.tfbackend
$ terraform plan -var-file=envs/dev/dev.tfvars
$ terraform apply -var-file=envs/dev/dev.tfvars