東京23区の賃貸マンションの家賃相場を階層ベイズで推定する(2024年12月版)
はじめに
階層ベイズモデルで東京23区の賃貸マンションの家賃相場を推定しました。
2024年12月にSUUMOをスクレイピングして約60万件の東京23区の賃貸マンションの家賃データを取得しました。家賃相場の階層ベイズモデルをStanとR(cmdstanr)で実装してモデルのパラメータを推定することで、東京23区の最寄り駅別の家賃相場や、築年数、駅徒歩分数、階数による家賃の押し上げ・押し下げ効果を推定しました。
最寄り駅ごとの家賃相場はSUUMOやHOME’Sなどの賃貸物件サイトで見ることができます。ただ、これらのサイトが公表している家賃相場は、何駅の1Kはいくら?くらいの粗い粒度です。面積が1m2違うだけでも数千円変わってきますから、例えば40m2で築5年で駅徒歩5分の物件はいくら?というような細かい家賃相場が知りたいですね。また、築10年の差はどの程度家賃相場が変わってくるのかも知りたいです。知りたいのですが、ここまで細かい家賃相場は知る限りネットに見つかりません。なければ自分で作る、というわけで実装しました。
ちなみにこのブログでは以前にも家賃相場のベイズモデリングに関する記事を書いています。
これらの記事でモデルは作れていたのですが、より安定した推定精度を得るためにデータ数を増やすなどいくつかのアップデートを行いました。
データ
データ取得と前処理
SUUMOの東京23区の賃貸マンションの物件一覧ページを2024年12月に1日1回ずつ、計2週間ほどスクレイピングしました。Python(requests + BeautifulSoup4)で実装しました。
ある一時点のデータでは、スクレイピングしたときにたまたま高級物件の募集が多かった駅の家賃相場が高く推定されてしまいます。複数日のデータを用意することで、単純にデータ数を増やせるだけでなく、このような影響を軽減できます。
複数日にわたって掲載されている物件は当然重複しますので、重複を除外します。それに加えてSUUMOでは同一の物件でも異なる物件として登録されていることがあるため、この重複も除外しました1。
そのうえで、分析やモデリングに使えるように前処理するとともに、データの誤入力や未入力と思われる物件を除外しました2。
ここまでで分析に使えるテーブルデータを作ることができました。以下のように、各行が個々の物件、列が特徴量のデータフレームです。87万件の物件データです。
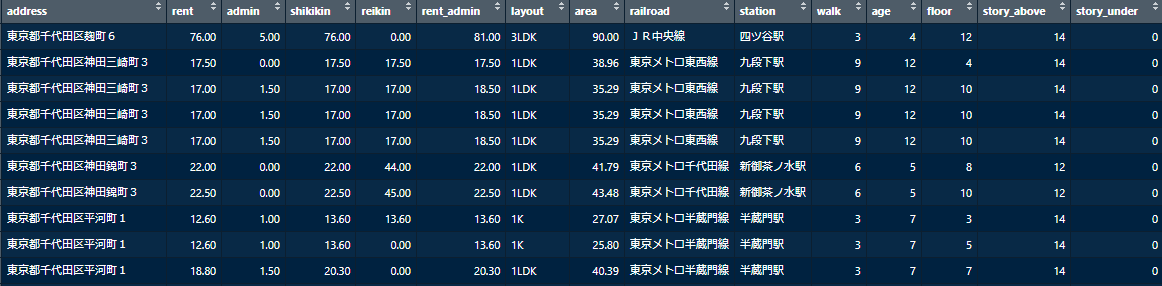
同じマンションに複数の物件の募集が出ている場合は物件数だけレコードがあります。
1行目の物件は、「千代田区麹町6丁目で家賃76万円、管理費5万円(家賃+管理費81万円)、敷金76万円、礼金0万円、3LDK、90m2、中央線四ツ谷駅から徒歩3分、築4年、12階(地上14階地下0階建て)」ということを意味します。81万円の賃貸ってすごいですね…。
なお、最寄り駅はSUUMOには最大3駅まで書いてありますが、簡単のため最初の1駅の情報のみを利用します。また、物件の構造(鉄筋か鉄骨かなど)、部屋の方角、物件の設備(バストイレ別かや食洗器が付いているかなど)のようなより詳細なデータはありません3。
使用するデータ
取得できたデータのうち、以下を満たす物件のみを家賃相場の推定に使います。
- マンションのみ
- 理由: アパートや一戸建ては家賃相場の推定上同一に扱えないため(築古による家賃押し下げ効果なども異なる)
- 間取りは1K, 1DK, 1LDK, 2K, 2DK, 2LDK
- 理由: 1Rはバストイレ一緒の物件が多いなど1K以上と同一に扱えないため除外、3K以上も物件数が少ないので除外4
- 家賃+管理費100万円以下
- 理由: 外れ値を除くため
- 面積は20m2~100m2
- 理由: 間取りと同様
- 築40年まで
- 理由: 築40年を超える物件は少ないため除外
- 駅から徒歩20分以内
- 理由: 23区内では徒歩20分を超える物件は少ないため除外
- マンションの階数(各物件の階数ではなく、建物自体の階数)は地上15階まで、かつ地下階はないか地下1階まで
- 理由: 16階建て以上の物件は少なく、タワーマンションのような高級物件となるので除外
ある程度均質なデータに絞るということです。外れ値の除外方法は工夫の余地があると思います。約62万件の物件データを用意できました。
モデル
家賃相場は、物件の最寄り駅、面積、築年数、駅からの徒歩分数、部屋の階数で決まると考えます。実際の家賃は部屋の設備のようなその他の特徴量にも左右されますが、おおむねこれらで決まると考えても大きくは外さないでしょう。以下、家賃とは家賃+管理費を指します。
物件$i(1, \dots, N)$の最寄り駅を$sta[i] (1, \dots, S)$とします。
$$ \begin{align*} \log{y_{i}} & \sim N(\mu_{i}, \sigma) \\\ \mu_{i} &= a_{sta[i]} + b_{sta[i]} \log{\mathrm{area}_{i}} \\\ &+ \beta_{\mathrm{age}} \mathrm{age}_{i} \\\ &+ \beta_{\mathrm{walk}}(\mathrm{walk}_{i} - 1) \\\ &+ \beta_{\mathrm{floor}} \max {(\mathrm{floor}_{i} - 2, 0)} \\\ &+ \beta_{\mathrm{isTop}} \mathrm{isTop}_{i} \\\ &+ \beta_{\mathrm{isGround}} \mathrm{isGround}_{i} \\\ &+ \beta_{\mathrm{isUnderground}} \mathrm{isUnderground}_{i} \\\ a_{sta[i]} & \sim N(a_{all}, \sigma_{a_{all}}) \\\ b_{sta[i]} & \sim N(b_{all}, \sigma_{b_{all}}) \\\ \end{align*} $$
このとき、物件の対数家賃の相場は$\mu_{i}$万円であると考えます。ただし、式中の変数は以下のとおりです。
- $y_{i}$: 家賃+管理費(万円)
- $\mathrm{area}_{i} (20 \leq \mathrm{area}_{i} \leq 100)$: 面積(m2)
- $\mathrm{age}_{i} (= 0, 1, \dots, 40)$: 築年数(新築は0年とする)
- $\mathrm{walk}_{i} (= 1, 2, \dots, 20)$: 最寄り駅からの徒歩分数
- $\mathrm{floor}_{i} (= -1, 1, 2, \dots, 15)$: 物件の階数
- $\mathrm{isTop}_{i} (= 0, 1)$: 最上階なら1, そうではないなら0
- $\mathrm{isGround}_{i} (= 0, 1)$: 1階なら1, そうではないなら0
- $\mathrm{isUnderground}_{i} (= 0, 1)$: 地下1階なら1, そうではないなら0
間取りの情報は入れていません。間取りと面積はかなり相関が強い変数であり多重共線性があるので面積のみをモデルに入れました。
最寄り駅によって同じ面積でも家賃相場が違うことを考慮しています。築浅や駅近、高層階ほど家賃が高いことや、最上階は家賃が高いこと、1階や地下階は家賃が安いこともモデルに織り込んでいます。あまり物件が存在しない最寄り駅でも、全体の傾向を踏まえてパラメータを安定して推定できるのが階層ベイズのメリットです。
ただし、このモデルでは以下のように単純化した定式化となっています。
- 築年数は1年増えるごとに、駅徒歩1分増えるごとに家賃相場が一定割合減る
- 1階高くなるごとに家賃相場が一定割合上がる
- 築年数、駅徒歩、階数や、1階や地下1階であることがそれぞれ家賃相場を押し上げる・押し下げる効果は、全ての最寄り駅で一定であり、その他の変数とは独立
これらは一定程度強い仮定であることに注意が必要です。
実際には、築浅物件と築古物件では、築1年経過することによる家賃の押し下げ効果は築浅物件の方が大きいと思われます。物件を検索するときは徒歩10分までのようなきりのよい値を指定することが多いため、徒歩10分と11分だと家賃相場が大きく変わるかもしれません。駅近ほどよいかというと、駅に近すぎると線路や駅周辺の騒音で家賃相場が安い可能性もあります。また、築古でも駅近や人気の駅、マンションの新規建設があまり行われていない地域では家賃が下がりにくいのも想像がつきます。
モデルのブラッシュアップの余地はありますが、大まかな傾向をつかめればよいということでこのモデルを採用します。
実装
環境はR=4.4.2, cmdstan=2.35.0, cmdstanr=0.8.1, bayesplot=1.11.1, tidybayes=3.0.7です。
上のモデルをStanで書きます。このコードを”model.stan”というファイル名で保存します。
data {
int N;
vector[N] Y;
vector[N] AREA;
int S;
array[N] int<lower=1, upper=S> STATION; // 最寄り駅index
vector[N] AGE; // 築年数(0 - 40)
vector[N] WALK; // 徒歩分数(1 - 20)
vector[N] FLOOR; // 階数(2 - 15; -1と1は2とする)
vector[N] IS_TOP; // 最上階かどうか(0/1)
vector[N] IS_GROUND; // 1階かどうか(0/1)
vector[N] IS_UNDERGROUND; // 地下1階かどうか(0/1)
}
parameters {
real a_all;
real b_all;
vector[S] a;
vector[S] b;
real<upper=0> age;
real<upper=0> walk;
real<lower=0> floor_num;
real<lower=0> is_top;
real<upper=0> is_ground;
real<upper=0> is_underground;
real<lower=0> sigma_a;
real<lower=0> sigma_b;
real<lower=0> sigma;
}
model {
a ~ normal(a_all, sigma_a);
b ~ normal(b_all, sigma_b);
log(Y) ~ normal(
a[STATION] + b[STATION].*log(AREA) +
age*AGE +
walk*(WALK - 1)+
floor_num*(FLOOR - 2) +
is_top*IS_TOP +
is_ground*IS_GROUND +
is_underground*IS_UNDERGROUND,
sigma
);
}
次に以下のRコードでstanコードをキックします。さきほど画像を載せたdata.frameをdf_uniqueという変数名で持っている前提です。
library(tidyverse)
library(cmdstanr)
library(bayesplot)
library(tidybayes)
df <- df_unique |>
filter(rent_admin <= 100) |>
filter(area <= 100 & area >= 20) |>
filter(age <= 40) |>
filter(walk <= 20) |>
filter(story_under <= 1L & story_above <= 15L) |>
filter(floor >= -1L & floor <= 15L) |>
filter(layout %in% c("1K", "1DK", "1LDK", "2K", "2DK", "2LDK")) |>
# Stanに入れるために、駅名をintegerに変換する
mutate(station_index=as.integer(as.factor(station))) |>
mutate(
# 平屋や2階建ての2階の場合は「最上階」とはみなさないことにする(その方が直感的に自然なので)
is_top=as.integer(floor == story_above & story_above >= 3),
is_ground=as.integer(floor == 1L),
is_underground=as.integer(floor <= -1L)
)
mod <- cmdstanr::cmdstan_model("model.stan")
fit <- mod$sample(
data=list(
N=nrow(df),
Y=df$rent_admin,
AREA=df$area,
S=length(unique(df$station_index)),
STATION=df$station_index,
AGE=df$age,
WALK=df$walk,
# 地下1階, 1階は"2"に変換して入れる
FLOOR=df |>
mutate(floor2=if_else(floor <= 1L, 2L, floor)) |>
pull(floor2),
IS_TOP=df$is_top,
IS_GROUND=df$is_ground,
IS_UNDERGROUND=df$is_underground
),
chains=4, parallel_chains=4, iter_warmup=1000, iter_sampling=1000, thin=1,
seed=1234, refresh=10
)
StanコードをRからキックするパッケージは、前の記事まではrstanを用いていましたが、cmdstanrに乗り換えました。コンパイルが早い、動作が安定していてクラッシュしにくい、開発が盛ん、OpenCLでGPUも使えるなどいいことづくめです。
warmupを入れて合計2000回のiterationで約2日かかりました。
結果
パラメータ
Rhat < 1.1であること以外にもStanによるMCMCの収束チェックは行いましたが、記事上は省略します5。
fit$print(
c("a_all", "b_all", "age", "walk", "floor_num", "is_top", "is_ground", "is_underground",
"sigma_a", "sigma_b", "sigma"),
max_rows=11, digits=3
)
#> variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
#> a_all -0.146 -0.146 0.016 0.016 -0.172 -0.120 1.001 7784 2950
#> b_all 0.839 0.839 0.006 0.006 0.829 0.848 1.001 7788 2648
#> age -0.012 -0.012 0.000 0.000 -0.012 -0.012 1.000 4176 2826
#> walk -0.008 -0.008 0.000 0.000 -0.008 -0.008 0.999 10482 2819
#> floor_num 0.009 0.009 0.000 0.000 0.009 0.009 1.002 9145 3069
#> is_top 0.000 0.000 0.000 0.000 0.000 0.000 1.001 5474 2358
#> is_ground -0.047 -0.047 0.000 0.000 -0.048 -0.046 1.000 8558 3008
#> is_underground -0.069 -0.069 0.002 0.002 -0.073 -0.065 1.004 10218 2805
#> sigma_a 0.333 0.333 0.012 0.012 0.315 0.353 1.000 5732 2706
#> sigma_b 0.119 0.119 0.004 0.004 0.113 0.126 1.000 7172 3115
#> sigma 0.109 0.109 0.000 0.000 0.109 0.109 1.000 3873 2026
築年数効果、駅徒歩分数効果、階数効果、最上階・1階・地下1階効果
パラメータageは事後分布の中央値が-0.0119でした。築年数が1年増えるごとに家賃相場の対数$\mu_{i}$が-0.0119小さくなることを意味します。つまり、築年数が1年増えるごとに家賃相場$\exp(\mu_{i})$は$\exp(-0.0119) = 0.988$倍になる、すなわち築年数が1年増えるごとに家賃相場は1.2%下がるということです。新築と比べると築5年は約6%、築10年は約11%家賃が下がることになります。
築1年経過するごとに家賃が1%下がるという経験則があるそうです。結果はこの経験則と整合的ですね。ただし今引用したレポートでは、築10年までの築浅物件とそれ以降の物件では前者の方が経年による家賃の下落率が高いと指摘されています。この点の考慮は今後の課題です。
同様に駅徒歩1分増えるごとに家賃相場は0.8%下がることが分かりました。
また、2階から見て1階上がるごとに家賃相場は0.9%上がります。また、1階と地下1階は2階から見てそれぞれ4.6%、6.7%家賃相場が下がります。is_undergroundのパラメータの95%信用区間の下限が0を上回らないことから、最上階であっても家賃は変わらないと言えることも分かりました。最上階はお得ですね!
例えば地上4階地下1階建てのマンションで2階が家賃10万円なら、3階は10.09万円、4階は10.18万円、1階は9.54万円、地下1階は9.33万円程度になる計算になります。だいぶ妥当な感じがします。1階は避けたがる人も多いですが、5%安いメリットを天秤にかけてどう判断するかですね。
最寄り駅ごとの家賃相場
25m2、新築、駅から徒歩5分、3階の物件を仮定して、この物件の最寄り駅別の家賃相場を求めてみましょう6。25m2というのは1Kや1DKでよくある面積です。特に1Kでは25m2~26m2というサイズの物件が非常に多いです。MCMCで得られた各パラメータのサンプリングされた値を用いて$\exp(\mu_{i})$の分布を求めることで計算できます。
JR中央線の新宿より西側を見てみます。
Code
draws <- tidybayes::spread_draws(
fit, a[station_index], b[station_index], age, walk, floor_num, is_top, is_ground, is_underground
)
station_index_table <- df |>
select(station, station_index) |>
distinct(station, .keep_all=TRUE)
# 駅名があればそのindex, なければNA_integer_を返す
station_to_idx <- function(station_name) {
chr <- station_index_table$station
idx <- station_index_table$station_index
if (length(idx[which(chr==station_name)]) == 0) {
return(NA_integer_)
} else {
return(idx[which(chr==station_name)])
}
}
Code
stations <- c(
"新宿駅", "大久保駅", "東中野駅", "中野駅", "高円寺駅", "阿佐ケ谷駅", "荻窪駅", "西荻窪駅"
)
idxs <- map_int(stations, station_to_idx)
AREA <- 25
AGE <- 0
WALK <- 5
FLOOR <- 3
IS_TOP <- 0
draws |>
filter(station_index %in% idxs) |>
# 駅名をプロットに表示するため
left_join(station_index_table, by="station_index") |>
mutate(station=factor(station, levels=rev(stations))) |>
mutate(
mu_exp=exp(
a + b*log(AREA) +
age*AGE +
walk*(WALK - 1) +
floor_num*max(FLOOR - 2, 0) +
is_top*IS_TOP +
is_ground*as.integer(FLOOR == 1L) +
is_underground*as.integer(FLOOR == -1L)
)
) |>
ggplot(aes(mu_exp, station))+
theme_minimal()+
tidybayes::stat_pointinterval(point_interval=tidybayes::median_qi, .width=0.95)+
theme(axis.title.y=element_blank(), axis.text=element_text(color="black"))
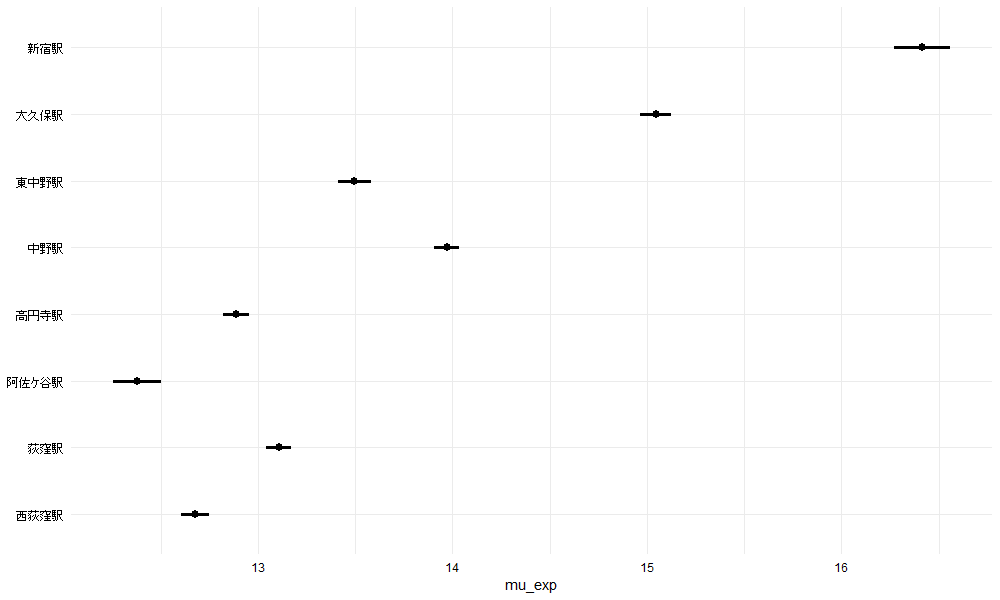
黒い点は事後分布の中央値、点の左右にある棒は95%ベイズ信用区間です。25m2の新築、徒歩5分、3階の物件は最寄り駅が荻窪駅だと黒い点より13.1万円くらい、棒より95%の確率で13.0万円 - 13.2万円くらいだということを示します。
なお、例えば築年数以外は同じ条件のまま築10年の家賃相場を考えてみると、築10年は新築と比べて約11%安くなることが分かっていますから、13.1万円 x 89% = 11万円後半になります。
12万円台後半~13万円の高円寺から西荻窪は駅によって街の特徴が分かれるところですが、個人的には西荻窪は商店街が個性的なお店やおいしいお店が多く魅力的です。新宿まで15分ですし、10分で中野に出て東京メトロの東西線にも乗り換えられて交通の便もいいですね。隣が吉祥寺なので買い物に困ることもないですね。
家賃相場の数値自体がどのくらい合っているかは評価が難しいところですが、最寄り駅ごとの相対的な違いとしては割と妥当に思われました。
さて、いま示した「家賃相場」とは何でしょうか?今回設定したモデルの下では、「荻窪駅から徒歩5分、新築、25m2、3階の物件の家賃の平均的な値」という確率変数$\exp(\mu_{i})$があり、これを「家賃相場」と呼ぶと、家賃相場の中央値は13.1万円であり、家賃相場の確率分布の95%は13.0万円 - 13.2万円の間に入るということを示します。
実際の物件の家賃は、この家賃相場にさらに$\sigma$というノイズが乗ったものとして観測される7ので、実際には13万円より安い物件も13.2万円より高い物件もありえます。ノイズには、バストイレ別かどうか、分譲賃貸かのようなモデルに入れていない特徴量や、その他説明が付かなかった物件固有のいろいろなものが含まれます。
おわりに
このモデルを参考にしながら物件を探してみたのですが、「掘り出し物の物件」というものはほとんどないんだなと思いました。グレードの高い物件はたいてい家賃相場から少し高めに設定されていましたし、家賃相場と比べて安い物件はエレベーターが付いていないなど、理由が何かしらありました。
東京23区だけでも1ヶ月で100万件近いデータが得られたように賃貸マンション市場は非常に大きい市場であるため、競争が働いていて効率的な市場になっているということなんですね。
なので掘り出し物の物件を見つけようというよりは、最寄り駅を変えるとどのくらい相場が変わるのかとか、築年数を10年下げる代わりに同じ家賃でどのくらい広い物件に住めるのかとか、物件探しのときの検討材料にするのがよさそうです。
このような目的としては統計モデリングが非常に効果的ですね。予測精度としてはLightGBMのような機械学習の決定木の特徴を持つ手法が優れていますし、LightGBMでもPartial Dependenceで似たような解釈ができます。
しかし、統計モデルには、最寄り駅ごとに家賃相場が異なるというようなデータ生成のメカニズムを明示的にモデルに織り込むことでドメイン知識を活用できるメリットがあります。また、ベイズモデリングによって、複雑な統計モデルであってもある程度パラメータを推定しやすいことや、パラメータの信用区間という形で何パーセントの確率でパラメータはこの範囲内であるというパラメータの確信度合いを示せることが、解釈性の高さにつながっています。
今後は築年数や駅徒歩分数の効果を非線形にするとか、家賃の外れ値のデータにロバストにするように正規分布ではなくt分布を導入するとか、モデルの高度化を進めてみたいです。
例えば、全く同じ物件でも、マンション名が「○○マンション」のように明記されているページと、「○○駅徒歩x分築y年」のように明記されていないページで複数回登場することがあります。住所、最寄り駅と最寄駅からの分数、築年数、物件の階数、家賃が全く同じでマンション名だけ異なる物件が複数回ある場合は重複を除外するようにしました。 ↩︎
詳細は階層ベイズで東京23区のお部屋の家賃相場を推定する#前処理をご参照ください。 ↩︎
これらのデータは各物件の詳細ページに載っています。物件一覧ページは1ページに数十件の物件が載っているため高速にスクレイピングできますが、詳細ページは1ページ1件のため時間の制約上現実的にスクレイピングできないので断念しました。 ↩︎
1SLDKのように納戸のある物件もありますが、これも除外しています。納戸は居室には使えない部屋なので、納戸の面積は家賃に与える影響がその他の部屋と異なる可能性があるため、モデルからは除外しました。 ↩︎
一般的に、[R] [stan] bayesplot を使ったモンテカルロ法の実践ガイド - ill-identified diaryのような内容をチェックします。詳細は階層ベイズで東京23区のお部屋の家賃相場を推定する#推定結果のチェックをご参照ください。 ↩︎
他に最上階ではないという条件も設定していますが、これまでみたように最上階かどうかは家賃に影響を与えないので、最上階だとしてもプロットは変わりません。 ↩︎
正確には、$\log y_{i} \sim N(\mu_{i}, \sigma)$で生成される$y_{i}$のexpを取ったものです。$\exp(\mu_{i})$は信用区間、$y_{i}$は予測区間を求めているという違いです。 ↩︎